

June 1, 2004
Automatic Web News Extraction Using Tree Edit Distance
|
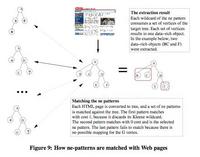
This is a paper that was in WWW2004. It's goal was to analyze a bunch of Brazilian news sites and pull out bits of the news story from them. Things like the title, the author and the content. The approach that they took was to crawl a bunch of news pages, then cluster them according to their template, generalize the template, then analyze the portions of the templates that were changeable for the things that they wanted. The key component of the research and the reason why I was interested was because they have a nice overview of work in tree-edit distances. This is the metric that compares two tree data structures and assigns a similiarity score to them. |
I think that something like this is going to become important to the work with the anesthesiologists because we are going to have to generalize the data stream that we receive from them in some way. I'm anticipating that we will have some structure for the activity provided, but have to generalize the rest and the tree approach seems pretty good.
The one caveat to using this technique is that I don't think that it is going to work very tightly with a probabilistic model because the basic assumption in the web sphere is that if you see something then it is intended to be there. In our case if we see something it might not have been intentional and if you don't see something, maybe you should have.
Posted by djp3 at June 1, 2004 1:00 PM | TrackBack (0)