- Okay I've got training data for the individual activities. That's 2 traces of 11 activities, mostly in the kitchen, all in the house.
- I started collecting a full run of all the activities when I ran out of juice in the gloves. I'm working with Matthai to get redundant gloves. The gloves work for about 8 minutes and then trail off, and I think I need about 30 minutes of data per run. If I'm not able to get in touch with Matthai by the end of today, I'm going to swing by IRS to see if I can find the charger and other gloves myself. Data collection is currently stalled.
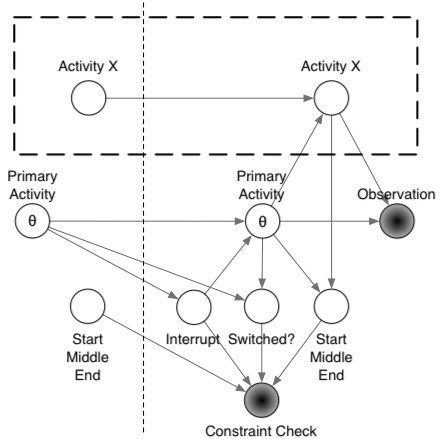
- Now I'm trying to figure out how to model this stuff scalably with the recently discovered limits of GMTK. These limits end up being about the per time-slice limits which I wasn't paying much attention to. I was focussing on the inter-temporal limits. The limits are:
- I can model four activities total, allowing complete interleaving, with the current model. That ends up being 233,280 states per second. That works for 30 minutes with half-second samples.
- I can model five activiites total, allowing complete interleaving, with the current model for only 15 seconds before I run out of memory. That uses 874.800 states per slice.
- Using the current model, I need about 8,418,025,440 states per second to do inference on the breakfast runs- not feasible with GMTK.
- So I put together a model in which only three activities can be interleaved at a time, although there are 11 total activities running. In order to do exact reasoning, this new model needs 1,138,484,160 states. Also not feasible with GMTK.
- So the conclusion seems to be to switch to particle filters. The big downside of this is that learning isn't implemented yet which is going to be hard to do in the time frame we've got. Nonetheless, I'm going to push ahead in this direction working with the code that I started at Intel this summer.
|